For a class on compiler design, I worked with a partner on a semester-long project to write a compiler from C0 (a typesafe subset of C – see the tutorial and the language reference) to x86 assembly in OCaml, making extensive use of Jane Street’s Core library. This was done in a series of project checkpoints.
The first checkpoint compiler only supported primitive mathematical computations on type int in a single main function. No control flow constructs or function declarations and calls were available in this language. After a few checkpoints, the compiler was able to support the full suite of features in C0. This included
- basic types, such as int, bool, char, string, and void, as well as pointers and bounds-checked arrays,
- control flow constructs, including conditionals, ternaries and loops, as well as supporting break and continue,
- function declarations and calls following the x86 calling conventions, including recursive functions,
- memory allocation and dereferencing, including struct declaration and use, and
- including header files using the #use directive.
The simple form of the compiler works as follows.
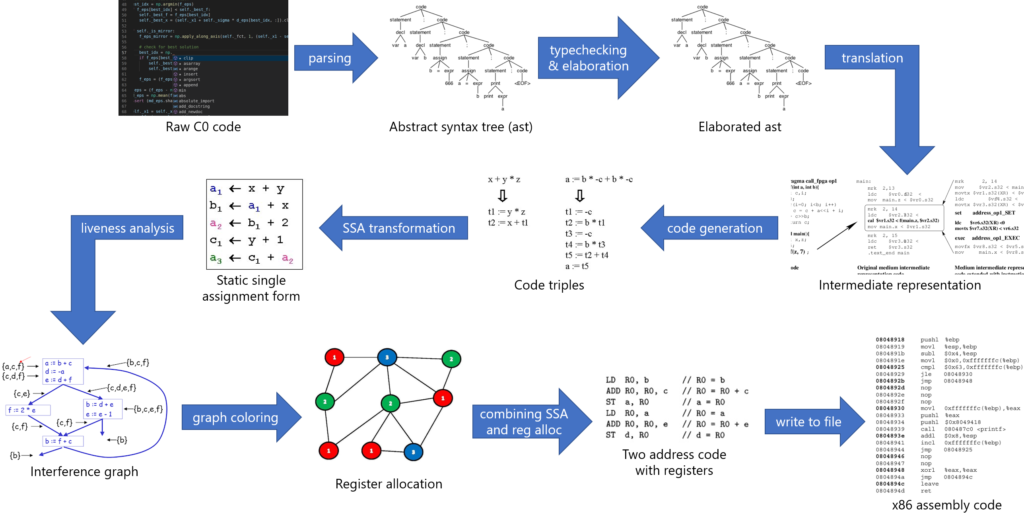
- An LR(1) parser was implemented using lex and yacc, generating an abstract syntax tree (ast) for the program.
- Typechecking was then performed using the statics of the language through a combination of checking and synthesis. Scoping and variable use was also checked in this stage.
- The ast was then elaborated to a primitive subset of instructions, such as elaborating for loops into while loops, boolean operators into ternaries and arrow operators into dereferences.
- The representation is translated into the intermediate representation (ir) which used a language that started to mostly look like x86 assembly instructions. Critical steps at this stage were to resolve struct accesses into pointer arithmetic and translate variables into temps.
- Code generation was then performed to transform the ir into a sequence of code triples on temporary variables (temps). It is at this stage that most of the syntactic sugar of C0 was eliminated. In particular, loops were translated into gotos, null struct and array size checking was noted where necessary (a feature of C0 that is not present in traditional C) and pre-allocation of registers was performed. Pre-allocation was necessary in cases such as during function calls (to ensure that x86 calling conventions were able to be adhered to later in register allocation) as well as when using assembly instructions where specific registers are part of the definition (such as idiv and imul).
- The code triples were then turned into static single assignment form, on which a liveness analysis was performed to generate an interference graph for the temps. Generating a tight liveness analysis required analyzing the dominator tree for code blocks within each function.
- Register allocation for the temps via graph coloring was performed using maximum cardinality search to generate a simplical elimination ordering. However, due to the pre-allocation of registers to satisfy x86 calling conventions, some modifications had to be made to the algorithm and some heuristics were used to ensure that no clashes with the pre-allocation would occur. For instance, temps to be spilled to the stack were determined using a cost metric taking into account its degree in the interference graph, number of uses in the code and loop depth. Preferentially spilling lower-cost temps would reduce the number of reads and writes required from and to the stack. The specifics and application of the heuristics were tweaked until they worked sufficiently well against the benchmarks.
- Finally, the code triples and the register allocation to temps was combined into into two-address code (which also served as a final check that the register allocation was valid), from which x86 assembly code was written to file.
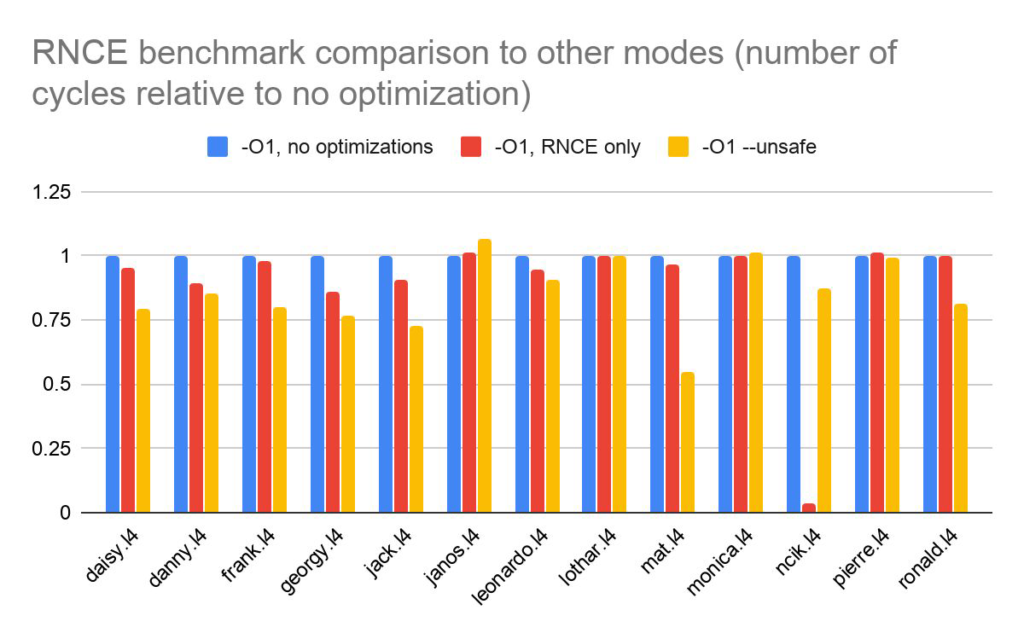
In addition, several compiler optimizations were implemented using dataflow analyses on the dominator tree, including sparse conditional constant propagation, dead code elimination and redundant null check elimination. With these optimizations we saw up to 25% speedup on some benchmarks. Most of my work was on implementing redundant null check elimination, which you can read more about in the appendices below.
As an extension to the project, the feature of generators was added to the source language, allowing programmers to yield intermediate values of a computation which is then suspended. The computation can then be resumed later to yield more values. These could be used, for instance, to simulate lazy lists as in functional languages.
In this project, my work was primarily in the typechecking, elaboration, code generation, register allocation and two-address code stages. My partner worked mostly on the parsing, translation, static single assignment transformation, liveness analysis and dataflow analysis stages.
Appendix: Redundant null check elimination
The implementation used a dataflow-based approach on the control flow graph (CFG) of the SSA form. In particular, the key insights are
- since every temp is only assigned to once, repeated null checks on the same temp can be removed, and
- if two temps are equivalent (i.e. an instruction of the form t1 ← t0 is found), and the source temp has been null checked, then the destination temp does not need to be null checked.
The dataflow analysis can be formalized as follows. The base cases are
in(v) = { } for all entry blocks v
check(v) = { t : NULLcheck t ∈ v, or ∃ t ← t' s.t. NULLcheck t' occurs earlier in block v or t’ ∈ in(v) }
and the dataflow analysis can be propagated by
in(v) = out(idom(v))
out(v) = in(v) ∪ check(v)
Running the compiler with only the redundant null check elimination optimization saw up to 15% speedup on some benchmarks. In particular, as expected, the largest speedups were found in programs with extensive use and manipulation of arrays and structs.
| C0 code | SSA (no optimization) | SSA (with RNCE) |
| | |